
Cuando los conjuntos de datos son difíciles de etiquetar o muy sesgados, el Aprendizaje Activo revela su gran potencial para ayudar tanto a los algoritmos como al analista a hacer que estos tengan sentido de forma más rápida y eficiente.
La promesa de una IA en ciberseguridad para ayudar a los humanos a automatizar y simplificar la abrumadora tarea de prevenir la fuga de datos mediante detección, seguimiento y bloqueo de software malicioso e intrusos lleva bastante tiempo con nosotros. La IA es una herramienta enormemente poderosa para esta tarea, pero a diferencia de lo que pasa en otras especialidades, obtener y etiquetar datos para entrenar cualquier tipo de motor/clasificador no es sólo caro, también complejo.
Consideremos el caso de Pinterest, por ejemplo: puedes hacer zoom en esos zapatos que te gustan tanto y la plataforma te mostrará una serie de fotos en las que aparecen los mismos zapatos o similares. Eso es útil y añade mucho valor a la experiencia. Obviamente, esto es posible porque hay muchas fotos de zapatos, bolsos, gente, perros y gatos. Los datos son abundantes y está disponibles y ahí es donde el Aprendizaje Profundo se luce.
Ahora pensemos en un software malicioso: los únicos datos realmente abundantes son los ficheros binarios. Hay gran cantidad de repositorios desde los que podemos descargar terabytes de ejecutables y ese es el motivo de que muchas compañías declaran tener sistemas de detección de binarios maliciosos mediante Aprendizaje Máquina. Los binarios son abundantes y están disponibles. Es un recurso que está al alcance de nuestra mano y en el que vale la pena invertir tiempo. Hablando de forma genérica, no es mala idea, a no ser que los binarios estén cifrados/empaquetados (¿a alguien le suena VMProtect?), en cuyo caso la detección estática falla por completo, tanto si está basada en Aprendizaje Máquina como si no.
Y ahora consideremos un ataque real: ahí es donde el Aprendizaje Máquina expone sus limitaciones, no porque la tarea sea demasiado compleja, sino porque los datos sobre ataques no son tan abundantes ni están tan disponibles. Además están escasa y, a menudo, complejamente etiquetados. Si lo están. Afortunadamente es difícil obtener muestras de 100.000 ataques diferentes, y con «ataque» nos referimos al conjunto de actividades ejercidas por un atacante. Tan solo el proceso de adquirir datos tras una brecha de seguridad es ya una árdua tarea. A menudo es difícil, incluso para un analista humano, detectar patrones comunes.
Mediante Aprendizaje Activo entrenamos un algoritmo de Aprendizaje Máquina de modo semi-supervisado, permitiendo que los motores consulten al analista cuando la el resultado de una predicción es incierto.
El siguiente experimento fue el resultado de una interesante conversación que mantuve hace unas semanas, tras dar una charla sobre como detectar cadenas de suministro de ataques en CIFI APAC en Singapur con varios expertos en ciber-seguridad de pequñas y grandes organizaciones de todo el mundo. La discusión dejó claro que el Aprendizaje Activo tenía que formar parte de nuestra plataforma, ReaQta-Hive, para ayudar a los analistas a realizar detecciones de forma más rápida y precisa incluso en ausencia de grandes librerías de muestras.
Tan sólo un recordatorio: entrenamos nuestro algoritmo de Aprendizaje Maquina mediante Aprendizaje Activo de forma semi-supervisada, permitiendo que los motores consulten al analista cuando el resultado de una predicción sea incierto. De algún modo, es como preguntar al profesor si una acción es correcta cuando estamos aprendiendo algo nuevo. En otras palabras, también significa que podemos incorporar conocimiento humano al proceso de aprendizaje, permitiendo a los motores entrenarse de forma eficiente con un conjuto de muestras limitado.
Para mostrar lo poderoso que es el Aprendizaje Activo, hemos preparado un experimento usando datos reales. Tomamos una base de datos interna de acciones de reconocimiento y movimientos laterales y la limitamos a sólo 1.000 entradas, de las cuales, la mitad, son actividades legítimas y la otra mitad maliciosas. Desde luego, una base de datos como esta no es representativa ya que hay muchas formas diferentes de iniciar un movimiento lateral y más aún de ejecutar tareas de reconocimiento, lo cual es, efectivamente, un problema real. Queremos dar respuesta a ciertas cuestiones:
- ¿Son los clasificadores capaces de converger más rápido cuando usamos Aprendizaje Activo?
- ¿Tiene una precisión comparable a la alcanzada por clasificadores completamente entrenados?
- ¿Cuál es el impacto de los errores (humanos) en la precisión global?
Empecemos con un experimento de referencia y continuemos desde ese punto.
Experimento de referencia
Primero necesitamos definir una referencia. Para esto hemos creado un sistema de aprendizaje profundo (Deep Learner) entrenado con un 75% del conjunto de datos sin sobreajuste, el otro 25% se usa para validación. Este es el resultado.
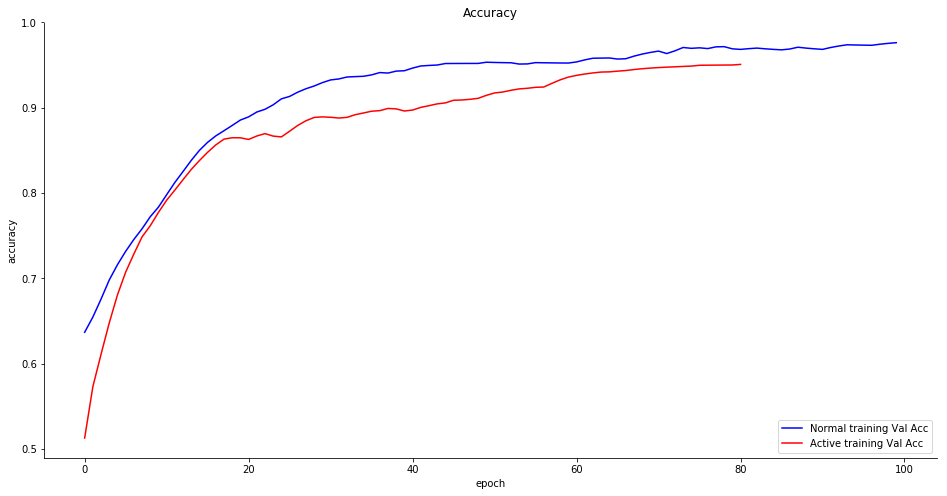
La precisión (K-fold=5) es del 93,8%, que no está mal para un conjunto de muestras tan pequeño y además no observamos sobreajuste. Entonces entrenamos el mismo clasificador con sólo el 15% del total de datos.
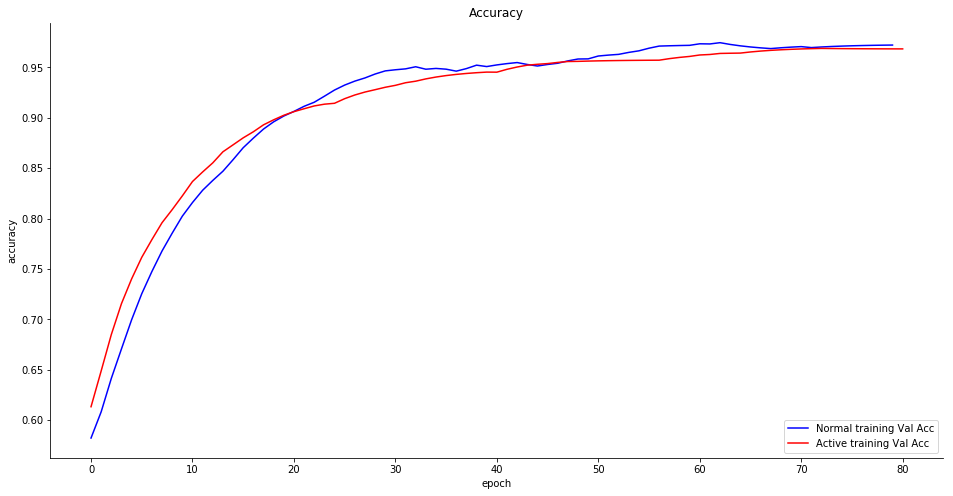
La precisión (K-fold=5) es del 86,9% con un importante sobreajuste que se hace patente al 14º ciclo, lo cual muestra que los datos son claramente insuficientes para entrenar correctamente el clasificador, incluso considerando que la precisión de la prueba no es mala en absoluto, lo cual indica que las características seleccionadas son relevantes y, potencialmente, el límite entre actividades maliciosas y normales no es tan difuso como podíamos pensar inicialmente. Y ahora vamos con la parte más interesante: el Aprendizaje Activo.
Experimento de Aprendizaje Activo
En el siguiente experimento hemos entrenado el clasificador con el 15% del conjunto de datos (solo 150 etiquetas únicas) en 12 ciclos – antes de empezar a experimentar sobreajuste – y a continuación pedimos al clasificador que haga una predicción con un pequeño conjunto de datos no etiquetados. Los clasificadores usan funciones softmax de forma que devuelven una probabilidad para cada clase (maliciosa y no-maliciosa) y le damos al clasificador la opción de pedir ayuda para asignar una clasificación cuando las predicciones más inciertas. Para simplificar: cuando la separación entre las dos clases no está clara, el clasificador puede pedir al analista que asigne una etiqueta al evento. Tras obtener algunas etiquetas, el clasificador se vuelve a entrenar con estos nuevos datos durante un número limitado de ciclos. Los resultados son inesperadamente positivos:
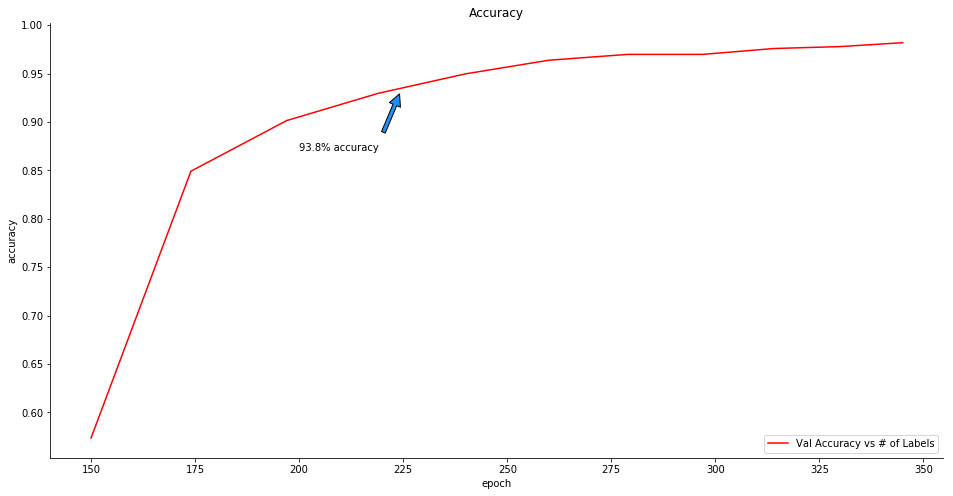
La aproximación mediante Aprendizaje Activo obtiene mejor rendimiento que el tradicional en tan sólo 6 ejecuciones. Y lo que es más interesante es que la aproximación por Aprendizaje Activo, con tan sólo 225 muestras etiquetadas (150 iniciales y 75 solicitadas al analista) ¡alcanza el mismo nivel de precisión que el obtenido con un entrenamiento normal a partir de 750 muestras etiquetadas! ¡Así que el entrenamiento por Aprendizaje Activo converge 3 veces más rápido que el normal! Además la precisión global resulta ser superior a la obtenida por la aproximación normal, alcanzando 98,6%, lo que lo convierte una vía que merece la pena investigar.
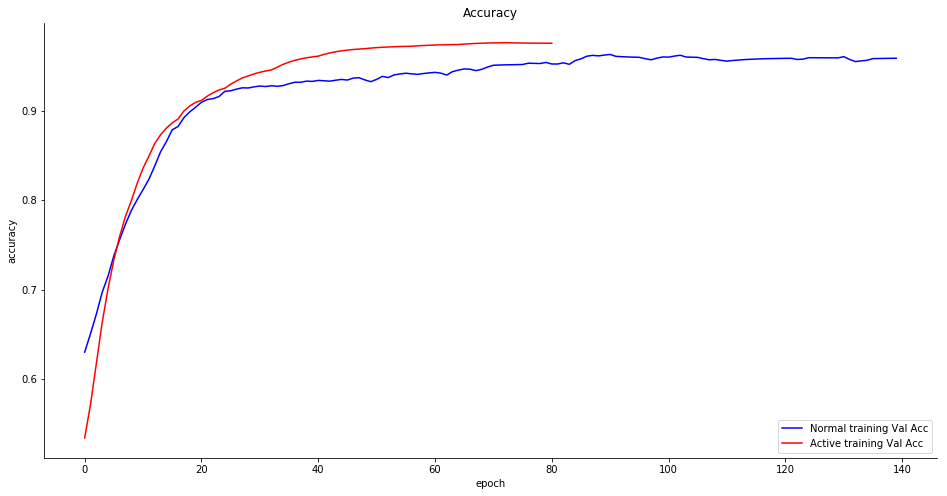
Gestionar los errores del analista: tasa de error del 5%
¿Qué pasa con los errores? El analista puede cometer errores cuando el sitema le pide que etiquete una muestra: este es el mismo experimento pero añadiendo un 5% de error a las respuestas del analista humano.
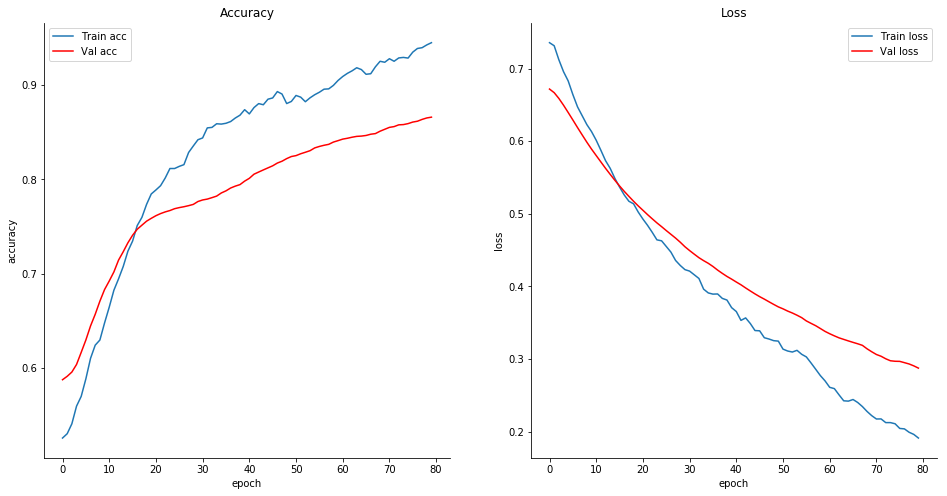
La precisión está a la par con el entrenamiento convencional y en general el sistema muestra resiliencia a los fallos de clasificación.
Gestionar los errores del analista: tasa de error del 20%
Esto es lo que ocurre con una tasa de error del 20%, es decir, cuando el analista etiqueta mal 1 de cada 5 solicitudes del sistema:
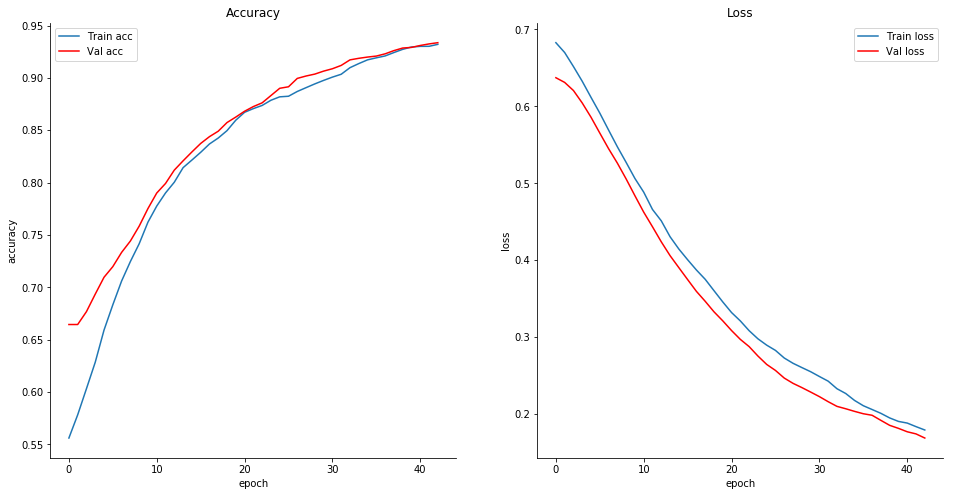
El clasificador lo sufre un poco comparado con la aproximación normal, pero al final es capaz de alcanzar una precisión bastante alta de todos modos.
¡Respondamos a las preguntas sobre Aprendizaje Activo!
Ahora podemos contestar a las preguntas que planteábamos al principio:
- ¿Son los clasificadores capaces de converger más rápido cuando usamos Aprendizaje Activo?
- Definitivamente sí. El conocimiento humano aportado ayuda a simplificar la tarea global, de modo que el clasificador es capaz de aprender más rápido cuando se compara con la aproximación tradicional.
- ¿Tiene una precisión comparable a la alcanzada por clasificadores completamente entrenados?
- Sorprendentemente, al menos en este experimento, parece ser aún mejor que la aproximación tradicional. Esto se debe al hecho de que las muestras verificadas se solicitan más a menudo de forma que el límite de decisión se regula más frecuentemente en los casos en que la separación es más difícil.
- ¿Cuál es el impacto de los errores (humanos) en la precisión global?
- Finalmente los clasificadores reaccionan bien a los errores hasta el punto de que un gran número de muestras etiquetadas erróneamente (20%) no impiden un buen desempeño sobre un periodo de entrenamiento más largo.
Conclusiones
El Aprendizaje Activo tiene mucho potencial en situaciones en las que los datos están sesgados, son escasos o muy caros/complicados de etiquetar. Es interesante destacar que las colecciones de muestras sesgadas parecen beneficiar más el aprendizaje activo: los clasificadores, de hecho, preguntan más a menudo cuando las muestras son escasas que cuando son abundantes. Por lo tanto se reduce el impacto de que las muestras no estén balanceadas, dado que los lotes de entrenamiento se remuestrean para evitar el sobreajuste de esas mismas etiquetas.
El Aprendizaje Activo añade valor incluso en esos contextos en que los datos son abundantes, por aceleración del proceso de aprendizaje, menor tiempo de convergencia y mayor precisión, concluyendo que los clasificadores se vuelven operativos más rápidamente, además de hacerse menos propensos a falsos positivos.
Aun hay muchas preguntas abiertas y serán parte de futuros experimentos. Por ejemplo, sería interesante entender si las muestras que resultan difíciles de etiquetar para los clasificadores también son difíciles para analistas humanos. Generar perfiles de los analistas a lo largo del tiempo también puede usarse como medio para modelar un clasificador en cascada que contribuya al proceso de aprendizaje. Por ejemplo, puede asignarse mayor peso a muestras proporcionadas por un analista que destaca por su habilidad para clasificar muestras de un determinado tipo mientras que se le asignaría un peso menor a las respuestas proporcionadas por otros analistas que serán mejores en la identificación de otros procesos.
Esta es un área de desarrollo muy emocionante que, debídamente aplicada, puede llegar a ser una parte fundamental de las interacciones entre humanos y máquinas en un SOC o Equipo de Seguridad.
Referencias
- Using Active Learning in Intrusion Detection (2004)
- Research on Query-by-Committee Method of Active Learning and Application (2006)